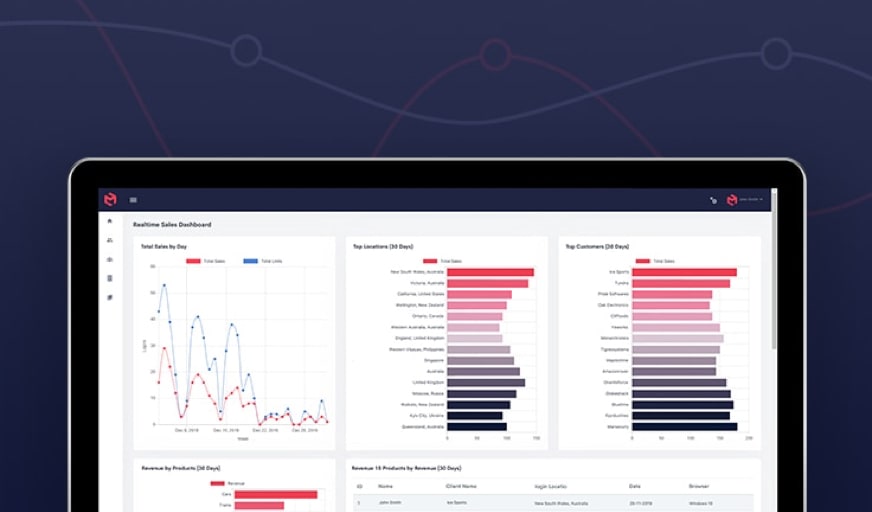
MODLR’s visual processes allow for low-code/no-code data transformation, with the versatile Visual Scripting Engine we launched recently. It is now available to all MODLR users.
Watch our first video for An Overview of the MODLR Visual Scripting Engine.
In this tutorial we explain how to build a visual process to load previously backed-up cube data from a CSV file into a selected target scenario. It provides a simple way to restore or migrate data by leveraging structured CSV inputs and writing them back into a cube.
What You Will Learn
- How to read structured CSV data.
- How to map and enrich that data
- How to write it back into a MODLR cube
- How to make the process reusable with dynamic inputs
The process is flexible and reusable. It allows users to dynamically choose the scenario at runtime. By combining CSV reading, data mapping, and cube updating, the workflow enables efficient and automated data loading with minimal manual effort.
Step-by-Step Summary
- Create a new visual process and name it.
- Add a CSV reader node to load the backup file.
- Add a cube update node to write data into the cube.
- Create a scenario argument for user input
- Use a map node to attach the scenario to each row.
- Connect the data flow between nodes.
- Configure the execution flow (CSV reader → map → cube update).
- Run the process.
This setup gives you a streamlined, repeatable and automated workflow for restoring cube data from CSV files. The process, made up of reusable components and dynamic inputs will help ensure consistency, while reducing the manual effort needed. It also makes data recovery or migration both efficient and reliable.
What happens when the process runs?
When executed:
- The CSV file is read row by row.
- The scenario is attached to each row.
- Data is written into the cube automatically.
What are the benefits of this approach?
- You end up with reusable workflows across datasets.
- Enables you to reduce manual effort.
- Consistent data structure.
- Efficient data restoration and migration.
When should you use this workflow?
You can use this process when you need to:
- Restore cube data from backups.
- Migrate data between environments.
- Load structured data, especially bulk data, into planning models.
Want detailed guidance?
READ the full video transcript of How to Load Cube Data from CSV into a Target Scenario for detailed guidance.
How to Load Cube Data from CSV into a Target Scenario - MODLR Visual Process Tutorial
In this tutorial, we walk you through how to create a visual process to load previously backed-up cube data from a CSV file into a target scenario. This approach allows you to restore or migrate data efficiently by reading structured CSV inputs and writing them directly into a cube.
We begin by creating a new process and giving it a descriptive name. Once we click okay, we are taken to the visual process workspace where we can start building the workflow.
First, we add a *CSV reader node*, which reads each row from the CSV backup file into a map of column headers and their corresponding values. Let us select and enter the file name of our CSV file. Once the file is selected, we can preview its contents to confirm that all elements and values are correctly structured. Next, we add a *cube update node*. This node takes the row data from the CSV reader and writes it into the cube. We then specify the target cube and define the value key, which corresponds to the column in the CSV containing the data values.
To make the process dynamic, we create an argument called *scenario*, allowing users to choose which scenario the data should be loaded into at runtime.You have to give it a name, a display label, and a description. You may also opt to use a default value. When you click the *add argument* button, this argument is incorporated into the data flow.
We will then drag the scenario argument into the process where it is needed. Then we insert a *map add to node* to attach the selected (user defined) scenario to each row of CSV data. Then we will add a new key named *scenario* and connect the scenario argument into its value. Then we connect the row data from the CSV reader to the map port of this node and the resulting enriched output into the cube update node.
Once the data path is configured, we then set up the execution flow. First run the CSV reader for each row. Connect the process row port to the map add to node. Finally we link the output of that to the cube update node.
Once everything is configured, our process is ready to run. When executed, it reads the CSV backup file, assigns the selected scenario to each row, and updates the cube automatically. This provides us with a streamlined and reusable way to restore cube data.
Want to learn more?
To explore this feature, you can book a demo today.