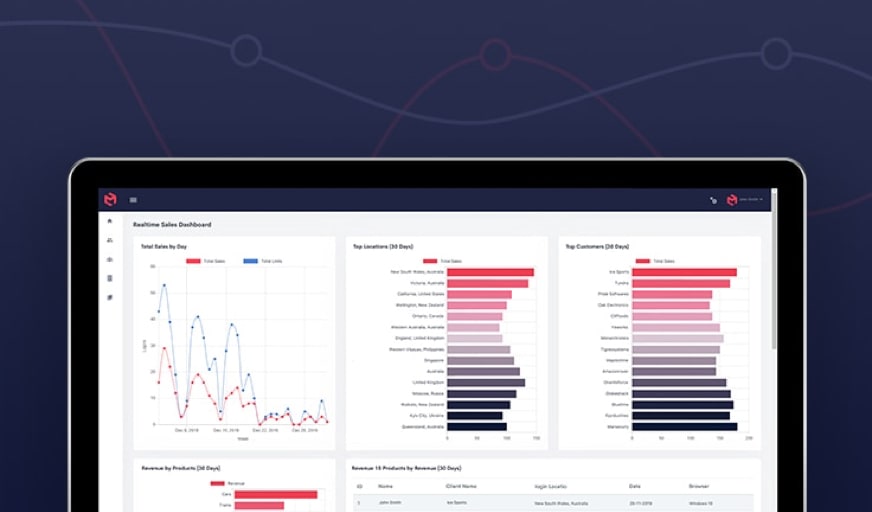
MODLR’s visual processes, supported by our versatile Visual Scripting Engine, allow for low-code/no-code data transformation. All MODLR users can now benefit from it.
Watch our first video for An Overview of the MODLR Visual Scripting Engine.
This tutorial outlines how to create a visual process to sync a local folder with an S3 directory. The goal is to ensure that only missing files are downloaded, avoiding unnecessary duplication and making the process efficient.
By combining S3 connectivity, file listing, conditional checks, and automated downloads, the workflow provides a simple and reusable way to keep local storage aligned with cloud data.
What are the key benefits?
This visual process ensures that only missing files are downloaded from S3. This helps avoid duplication and improves process efficiency. It can:
- Reduce redundant downloads
- Save bandwidth and storage
- Automate file synchronization
- Keep local data up to date
- Provide you with a reusable and scalable workflow
Can this process be reused?
Yes. The visual workflow can be reused for any S3 folder or extended to multiple directories.
Who should use this?
Anyone using MODLR who wants an automated, low-code way to sync their cloud storage with local files can benefit from this process.
How do you sync a local folder with an S3 directory in MODLR?
You can sync a local folder with an S3 directory in MODLR by creating a visual process that connects to S3, lists files, checks their existence locally to download only the missing files. This way, there is efficient synchronization without duplicating existing data.
Here’s a Step-by-Step Summary on How to Sync an S3 Directory
- Create a new visual process
- Configure an S3 connection
- List files from the target S3 folder
- Loop through each S3 object
- Store object metadata in a variable
- Build the local file path
- Check if the file exists and is valid
- Apply conditions to determine if download is needed
- Download missing files from S3
Syncing is now complete!
In short, automating S3 file synchronization in MODLR involves creating a visual process, connecting to S3, listing files, looping through objects, checking file existence, applying conditions, and downloading only missing files. This creates a streamlined and efficient sync workflow.
This process gives you a reliable and automated method for keeping a local folder synchronized with an S3 directory. By only downloading files that are not already present, it improves efficiency, reduces redundancy, and ensures your local data stays up to date with minimal effort.
How can you download only missing files from an S3 bucket?
To download only missing files from an S3 bucket, you can use conditional checks in a workflow. First you need to verify if a file exists locally. Then you must apply a condition to proceed only if it is missing. This two step process prevents duplicate downloads and optimizes performance.
Can a MODLR S3 sync workflow be reused across multiple folders?
Yes, you can reuse a MODLR S3 sync workflow across multiple folders. The process is designed to be flexible and scalable which allows you to apply the same logic to different S3 directories or, if needed, to extend it for broader automation use cases.
Watch Other Visual Process Videos from MODLR
Visual Process Overview- A MODLR Visual Process Tutorial
How to Use a Forex API to load Exchange Rates into a Cube - A MODLR Visual Process Tutorial
How to Load CSV into Cube - A MODLR Visual Process Tutorial
Want detailed guidance?
READ the full video transcript of How to Sync an S3 Directory for detailed guidance.
Syncing a Local Folder with an S3 Directory - A MODLR Visual Process Tutorial
In this tutorial, we build a visual process that synchronises a local folder with an S3 directory by downloading only the files that are missing. This approach ensures efficient file management by avoiding duplicate downloads and keeping the local environment aligned with cloud storage.
As we need a connection to S3, we begin by setting up an *S3 connection node*, where we configure the required credentials, region, and bucket. This connection node will be used by all S3-related actions within the process and can securely use stored access keys and secrets.
In this example, we are going to supply the AWS access key and the AWS secret key from our instance secrets.
Once the connection is ready, we will want to get a list of all the files in a folder on S3 that we wish to sync. So we will add a *S3 list object node* and connect it to the S3 connection.
When we provide a prefix (the folder path), this node will output a list of objects in that S3 directory containing metadata including file name, object key and size.
To process each file individually, we introduce a for each list node, which iterates through the S3 objects. For better organisation, the metadata for each object is stored in a variable, making it easier to reference throughout the workflow.
You can see a visual representation of what this list of objects may look like.
We need to check if we already have each file in our local directory for each list node so that we can process each item in this list of S3 objects. We need to construct the destination path for each file on the local system.
To make the visual process tidy, we store the S3 metadata in a variable that we can use throughout the rest of the visual process. We will call it *object* and add a variable set node to apply this object to our new object variable.
Next, we need to assemble where the file should live on our MODLR instance. This is done using a string concatenate node to combine the local folder path with the file name from the S3 object. The result is stored in an output path variable for reuse.
In this example, we are using the local folder called S3_demo. While it is possible to fetch variables via nodes and port connections, here’s how to reference them directly, including nested values like our S3 objects file name or other variables inside double brackets.
Because we need to use this in multiple places, we store it in a variable called *output_path*. Let us go ahead and set this new variable the same way we did earlier.
Before downloading any file, we should check two things: that it doesn’t already exist locally and that the S3 object is actually a file. This ensures efficiency and accuracy.
Adding a *file exist* node verifies whether the file already exists locally. Adding a *negate* node ensures the process continues only if the file is missing.
An additional condition—adding an *equals* node—checks that the S3 object is a file rather than a directory. Here we can reference the type field inside our object variable using double brackets.
These conditions are combined using an *And* node. Finally we add a branch node to evaluate this combined condition.
If the condition is met, we need to download the file. We’ll add an *S3 download file* node connecting it to the true output of the branch node. This node uses the *S3 object key* and the output path variable we created. Finally connect your existing S3 connection to the connection port.
When the process runs, it iterates through all files in the specified S3 directory and downloads only those that do not already exist locally. The result is a streamlined and automated way to keep a local folder in sync with an S3 bucket.
Want to learn more?
To explore this feature, you can book a demo today.